Yassine EL KHALThe complete guide to string similarity algorithmsIntroduction14 min read·Aug 21, 2023--4--4
Yassine EL KHALThe probability to win a Tennis matchHow likely is it that the best player is going to win8 min read·Apr 24, 2023----
Yassine EL KHALEntropy, Cross-Entropy, Mutual information and Kullback-Leibler divergenceAn introduction to information theory9 min read·Aug 17, 2022--1--1
Yassine EL KHALCovariance, correlation and R-squaredThe complete guide to understand covariance, correlation and R²8 min read·Mar 28, 2022--1--1
Yassine EL KHALHow your loan monthly payments are calculatedUnderstanding what’s behind the bank rate.5 min read·Sep 7, 2021----
Yassine EL KHALVariance and standard deviationThe complete guide to understand variance and standard deviation7 min read·Jul 27, 2021----
Yassine EL KHALConfusion matrix, AUC and ROC curve and Gini clearly explainedUnderstanding the confusion matrix, AUC and ROC curve with their implementations8 min read·Mar 18, 2021--1--1
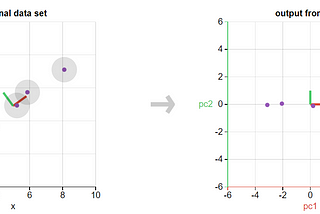
Yassine EL KHALIntroduction to Principal Component Analysis (PCA)Learn PCA with its interpretation and its implementation in R6 min read·Oct 8, 2020----
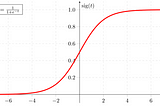
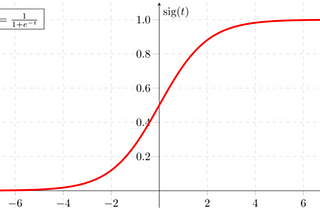
Yassine EL KHALIntroduction to Logistic RegressionLearn how logistic regression is implemented from scratch6 min read·Aug 25, 2020----