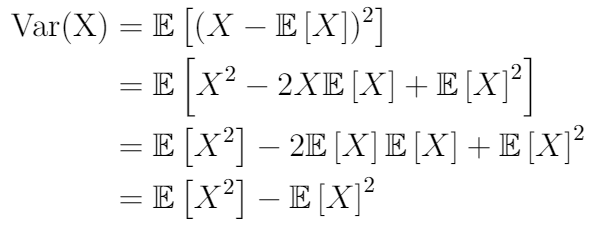Member-only story
Variance and standard deviation
The complete guide to understand variance and standard deviation

Descriptive statistics are used to describe the basic information about the data. They help us understand some features of the data by giving short summaries about the sample. It’s like the first impression of what the data shows us. In a nutshell, descriptive statistics are metrics and quantitative analysis to briefly describe our sample. And they’re broken down into measures of central tendency and measures of variability. In this article, we’ll discuss the latter and we’ll clear the fog on famous questions about variance and standard deviation.
Variance
Definition
Suppose that we have a random variable, by definition, it can take different values. The distribution of this random variable is what determines its range and its variation. Now we want to have a metric to measure how much this variable varies. This is what we call variance: it’s a metric to describe the spread between data set from its mean value. It can also be seen as the measure of the width of a distribution but this is more related to normal distribution as for other distributions.
Mathematically, in a population, we can calculate it as: the mean of the square distance between each point and the mean, this is correlated with how far each point in the data set is from the mean.
This formula can be expressed more generally and more directly as following because the expected value of a random variable in a population is just its mean.
There’s also another formula for variance, it’s another view of how we perceive the notion of dispersion and it’s more simple and elegant.
This one says: Variance is the difference between the expected value of squared inputs and the square of the expected value of the input.
Even though this formula is simple but it stays less interpretable than the first one. We can just see it as a simplification of the other one.